Exercise 2.6.16. Consider the space of 2 by 2 matrices. Any such matrix can be represented as the linear combination of the matrices

that serve as a basis for the space. Find a matrix  corresponding to the linear transformation of transposing 2 by 2 matrices, and explain why
corresponding to the linear transformation of transposing 2 by 2 matrices, and explain why  .
.
Answer: Each of the elementary 2 by 2 matrices can be considered as equivalent to one of the elementary vectors in 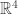

(Simply read off the entries in the 2 by 2 matrices starting with the first row left to right and then the second row left to right.)
We want to transpose each of the elementary 2 by 2 matrices into the following matrices:

corresponding to the following vectors in

In other words we must have  ,
,  ,
,  , and
, and  .
.
Since when multiplying the first row of by the entries of 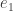 (which produces the first entry in the resulting vector) we must produce 1, and when multiplying the second through fourth row of by the entries of we must produce 0. This means must look as follows:
(which produces the first entry in the resulting vector) we must produce 1, and when multiplying the second through fourth row of by the entries of we must produce 0. This means must look as follows:
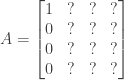
Note that we don’t care what the other entries in are, since when multiplying those entries will end up multiplying zeroes:

Since when multiplying the first row of by the entries of 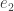 we must produce 0, and similarly when multiplying the second and fourth rows of by the entries of . However when multiplying the third row of by the entries of (which produces the third entry in the resulting vector) we must produce 1. This means must look as follows:
we must produce 0, and similarly when multiplying the second and fourth rows of by the entries of . However when multiplying the third row of by the entries of (which produces the third entry in the resulting vector) we must produce 1. This means must look as follows:

Note again that we don’t care what the other entries in are, since when multiplying those entries will end up multiplying zeroes:

We next have so when multiplying the second row of by the entries of 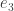 we must produce 1, and when multiplying the other rows of by the entries of must produce 0. This means must look as follows:
we must produce 1, and when multiplying the other rows of by the entries of must produce 0. This means must look as follows:

so that

Finally since when multiplying the first, second, and third rows of by the entries of  we must produce 0, and when multiplying the fourth row of by the entries of we must produce 1. This means must look as follows:
we must produce 0, and when multiplying the fourth row of by the entries of we must produce 1. This means must look as follows:

with

Combining the above results we see that

Note that we could have achieved the same result by having each column of be the vector into which the corresponding elementary vector should be transformed. In other words, the first column of should be (since transforms into ), the second column should be (since transforms into ), and similarly the third and fourth columns should be and respectively.
When multiplying by itself we see that

In other words, applying twice to a given vector leaves that vector unchanged. This effect can be explained in multiple ways.
First, when applied to vectors in the matrix permutes the second and third entries of the vectors but leaves the first and fourth entries unchanged:

Applying again reverses the effect of the permutation of the second and third entries, again leaving the first and fourth entries unchanged, and thus restores the original vector.
Second, when applied to our original space of 2 by 2 matrices has the effect of transposing a matrix, transforming

into
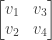
Applying twice has the effect of taking the transpose of the transpose. Since 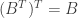 for any matrix
for any matrix  this has the effect of restoring the original 2 by 2 matrix.
this has the effect of restoring the original 2 by 2 matrix.
NOTE: This continues a series of posts containing worked out exercises from the (out of print) book Linear Algebra and Its Applications, Third Edition by Gilbert Strang.
by Gilbert Strang.
If you find these posts useful I encourage you to also check out the more current Linear Algebra and Its Applications, Fourth Edition , Dr Strang’s introductory textbook Introduction to Linear Algebra, Fourth Edition
, Dr Strang’s introductory textbook Introduction to Linear Algebra, Fourth Edition and the accompanying free online course, and Dr Strang’s other books
and the accompanying free online course, and Dr Strang’s other books .
.
 Buy me a snack to sponsor more posts like this!
Buy me a snack to sponsor more posts like this!
 and
and  , a linear transformation
, a linear transformation  in
in  in
in  using function notation. (For clarity I’ll continue to use function notation for the rest of this post.)
using function notation. (For clarity I’ll continue to use function notation for the rest of this post.)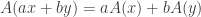
 and
and  in
in  and
and  that could be used to multiply vectors in
that could be used to multiply vectors in 

 and
and  in
in  and any scalars
and any scalars  and
and  that could be used to multiply vectors in
that could be used to multiply vectors in  .
. . Since
. Since 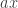 and
and  are also vectors in
are also vectors in 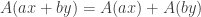 . By the same definition we also have
. By the same definition we also have 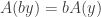 so that
so that 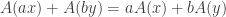 . Combining the equations we see that
. Combining the equations we see that  and reduces to
and reduces to 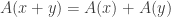 if
if 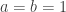 .
.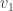 ,
, 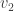 , through
, through 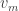 in
in 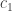 ,
, 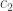 , through
, through 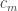 . Then we have
. Then we have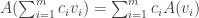
 from the definition in (1) above we have
from the definition in (1) above we have

 we have
we have
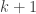 we have
we have


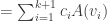
 and is also true for
and is also true for  .
. to
to 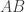 to be
to be  for all
for all  in
in  is a vector in
is a vector in 

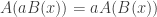
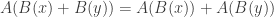


 from a vector space
from a vector space  to
to  is the same as applying
is the same as applying 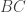 then
then  . (In other words, composition of linear transformations is associative.) For the proof of this see the
. (In other words, composition of linear transformations is associative.) For the proof of this see the  is a linear transformation from
is a linear transformation from 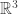 to itself, or more generally from any vector space
to itself, or more generally from any vector space 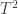 is also a linear transformation.
is also a linear transformation. of two linear transformations is also a linear transformation, again from
of two linear transformations is also a linear transformation, again from 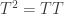 is a linear transformation if
is a linear transformation if  since
since  is the result of applying
is the result of applying 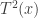 to mean
to mean 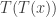 . In other words,
. In other words,  for any
for any 

 we see that
we see that  in
in  .
.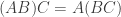 ?
? in
in 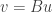 in
in 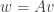 in
in  .
. . Since the first step, namely applying
. Since the first step, namely applying  .
.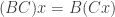 .
. . But from the previous answer we also know that
. But from the previous answer we also know that  and thus that the linear transformations
and thus that the linear transformations ![[C]](https://s0.wp.com/latex.php?latex=%5BC%5D&bg=ffffff&fg=333333&s=0&c=20201002) constructed using the chosen basis vectors in
constructed using the chosen basis vectors in ![[B]](https://s0.wp.com/latex.php?latex=%5BB%5D&bg=ffffff&fg=333333&s=0&c=20201002) constructed using the chosen basis vectors in
constructed using the chosen basis vectors in ![[A]](https://s0.wp.com/latex.php?latex=%5BA%5D&bg=ffffff&fg=333333&s=0&c=20201002) constructed using the chosen basis vectors in
constructed using the chosen basis vectors in ![([A][B])[C]x = [A]([B][C])x](https://s0.wp.com/latex.php?latex=%28%5BA%5D%5BB%5D%29%5BC%5Dx+%3D+%5BA%5D%28%5BB%5D%5BC%5D%29x&bg=ffffff&fg=333333&s=0&c=20201002) . Any matrix can represent a linear transformation, so we then have
. Any matrix can represent a linear transformation, so we then have ![([A][B])[C] = [A]([B][C])](https://s0.wp.com/latex.php?latex=%28%5BA%5D%5BB%5D%29%5BC%5D+%3D+%5BA%5D%28%5BB%5D%5BC%5D%29&bg=ffffff&fg=333333&s=0&c=20201002) for any three matrices
for any three matrices 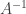 exists such that
exists such that  show that
show that  is the matrix representing
is the matrix representing 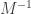 .
.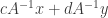 for any
for any ![cA^{-1}x + dA^{-1}y = A^{-1}[A(cA^{-1}x + dA^{-1}y)]](https://s0.wp.com/latex.php?latex=cA%5E%7B-1%7Dx+%2B+dA%5E%7B-1%7Dy+%3D+A%5E%7B-1%7D%5BA%28cA%5E%7B-1%7Dx+%2B+dA%5E%7B-1%7Dy%29%5D&bg=ffffff&fg=333333&s=0&c=20201002)
![A^{-1}[A(cA^{-1}x + dA^{-1}y)] = A^{-1}[cA(A^{-1}x) + dA(A^{-1}y)]](https://s0.wp.com/latex.php?latex=A%5E%7B-1%7D%5BA%28cA%5E%7B-1%7Dx+%2B+dA%5E%7B-1%7Dy%29%5D+%3D+A%5E%7B-1%7D%5BcA%28A%5E%7B-1%7Dx%29+%2B+dA%28A%5E%7B-1%7Dy%29%5D&bg=ffffff&fg=333333&s=0&c=20201002)
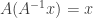 and
and  so that
so that![A^{-1}[cA(A^{-1}x) + dA(A^{-1}y)] = A^{-1}(cx + dy)](https://s0.wp.com/latex.php?latex=A%5E%7B-1%7D%5BcA%28A%5E%7B-1%7Dx%29+%2B+dA%28A%5E%7B-1%7Dy%29%5D+%3D+A%5E%7B-1%7D%28cx+%2B+dy%29&bg=ffffff&fg=333333&s=0&c=20201002)

 is the matrix representing
is the matrix representing  represented by the product matrix
represented by the product matrix 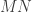 and
and 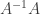 represented by the product matrix
represented by the product matrix  .
. . We therefore have
. We therefore have  and
and 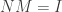 which implies that
which implies that 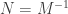 .
. is the reflection matrix in the
is the reflection matrix in the 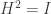 using the trigonometric identity
using the trigonometric identity 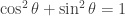 (
(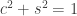 for short).
for short).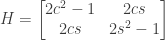
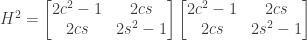

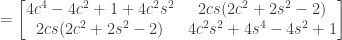
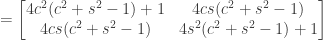
 this can be simplified to
this can be simplified to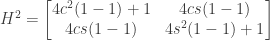
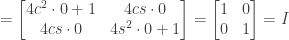
 for which
for which  . From the previous exercise we can express any such function as
. From the previous exercise we can express any such function as 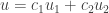 where
where  and
and  are basis vectors for W.
are basis vectors for W.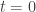 we have
we have 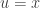 and
and  . Find
. Find  into the vector space
into the vector space  and
and  for
for  and
and 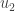 for
for 


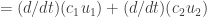
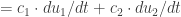





 or
or
 or
or
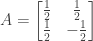
 is in
is in 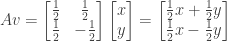


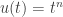 for some
for some  ) because differentiating a polynomial of degree
) because differentiating a polynomial of degree  (
( ) and taking the second derivative produces a polynomial of degree
) and taking the second derivative produces a polynomial of degree 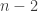 (
(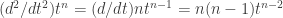 ).
).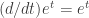 (see for example the
(see for example the 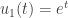 we then have
we then have
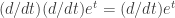
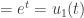
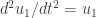 .
.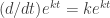 (this follows from the
(this follows from the 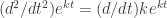
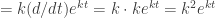
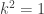 which is true if
which is true if 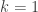 or
or 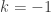 . The case
. The case 



 .
. . For all such functions we have
. For all such functions we have



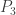 , the space of cubic polynomials in
, the space of cubic polynomials in  to produce a polynomial in
to produce a polynomial in 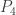 , the space of polynomials in
, the space of polynomials in  (representing the constant term),
(representing the constant term), 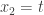 ,
, 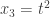 , and
, and 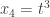 .
. will have 4 columns because there are 4 basis vectors of
will have 4 columns because there are 4 basis vectors of 

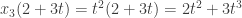


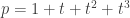 . Using matrix multiplication we have
. Using matrix multiplication we have


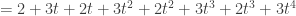

 ? What are the nullspace and column space of this matrix? What polynomials would they represent?
? What are the nullspace and column space of this matrix? What polynomials would they represent? . The first derivative
. The first derivative  of such a polynomial is
of such a polynomial is  and the second derivative
and the second derivative  .
. (representing the constant term),
(representing the constant term), 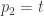 ,
,  , and
, and 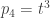 then the polynomial
then the polynomial  .
. ,
, 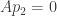 ,
,  , and
, and  . The resulting matrix is
. The resulting matrix is

 .
.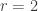 .
. is the set of all vectors
is the set of all vectors 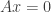 or
or
 and from the second row
and from the second row  so that
so that 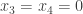 . In this case
. In this case  and
and  are free variables that can take on any value. The null space is therefore the set of all vectors of the form
are free variables that can take on any value. The null space is therefore the set of all vectors of the form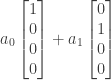
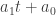 . The nullspace has rank
. The nullspace has rank  .
.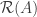 is the set of all linear combinations of the last two columns of
is the set of all linear combinations of the last two columns of 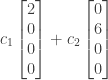

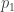 through
through 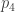 . Thanks go to Abdalsalam Fadeel for pointing out a mistake with this.
. Thanks go to Abdalsalam Fadeel for pointing out a mistake with this.
